

Refactoring the TestFarm server
 I spent some time refactoring the TestFarm server
for scalability and maintenability.
TestFarm is a continuous integration platform
we implemented for CLAM and other projects.
I spent some time refactoring the TestFarm server
for scalability and maintenability.
TestFarm is a continuous integration platform
we implemented for CLAM and other projects.
Read more to know why and how this refactoring took place.
That’s the thing: CLAM TestFarm server and the client doing the build for Linux were hosted by Barcelona Media, but, since none of the active CLAM developers, neither Pau or Nael or Xavi or me, are working anymore for them, we are not going to ask them to keep that box alive. Thanks to Barcelona Media for hosting it all those many years!!
The only public available hosts we have are in DreamHost, including clam-project.org, and they can not stand the current TestFarm server load.
Barcelona Media server hosted both, the client doing the Linux build and the server generating the website. We recently noted with surprise that, as the time goes on and more executions are logged into the server, the load came more from the website generation than from the actual Linux build. So the whole idea is to refactor the scalability flaws we found at the website generation, and move just the website generation to clam-project.org, while keeping the clients on private machines. Hey, one client can be yours!
How TestFarm works
Just in case you are not familiar with TestFarm let me introduce a little it’s work-flow. A team is working distributedly on a project hosted on some source code repositories (git, svn…). Project volunteers deploy TestFarm clients on their private machines to cover a range of supported platforms. TestFarm clients monitor the repositories for updates on the code base. When they detect an update, an execution starts, (compilations, tests… whatever) and they send the execution events to the server. The TestFarm server logs those events and builds a website with all that information.
Similar systems work in a different way: On those systems server is a master that tells its slaves to build for him a given revision of the code. TestFarm is thought with volunteers in mind. The clients are the ones that decide how often they check for the repository and the whole transaction is controled by the client, so you don’t need a fixed IP or a 24/7 connected server.
For consistence I changed the meaning of some of the terms used in TestFarm. The short glossary at the end of this article may help as reference.
The flaws
Long logs parsed once and again. At some point of TestFarm development, clients stalled when reporting their events because they had to wait for the webservice to regenerate the website. This was naively solved by moving web generation away from the web service to a cron job so that the web server just added entries into a monolithic log. That solved client stalls but made heavier web generation as the parsing of the monolithic log took a lot of memory and was done once and again.
Coupled generation and logging. Whenever we tried to fix the former flaw, by changing the structure of the logs to fit their usage, we hit a harder problem. Website generation was accessing directly the information from the logs, for different files to obtain different information. Changing the structure of the logs, affects a lot of code.
Lack of tests for web file generation. The generated files for the website had no tests backing them, so whenever you tried to do the former changes you were not able to know whether the output changed.
Lack of context for log events. Log events mimics the events of a local TestFarm execution and that’s not appropiate. In a local execution you just have a single client, and events occurs sequentially, so whenever you start a command you know its part of the last started task. You cannot make this assumption when playing with different clients unterminated executions… So the context cannot be implicit, and the event must have the whole information.
(Re)Design principles
Encapsulated logs. In order to be able to change the logs structure easily, access to the logs for reading and writting has to be encapsulated under a class, Server. This class provides two interfaces: The logging interface will be one exported as web service to the clients, and by manipulating it we can simulate a given client situation for testing. The information gathering interface is used by the code generating the website, and provides a semantic way of accessing information from the logs. Instead of accessing log event lines, and interpreting them, the Server class provides the semantics that we tried to derive from the logs.
All the state is on the log files. A different server instance is created each time a client logs an event. And we use a different Server instance to generate the website. All the state of the Server class should be built on the log files, any information holded by the Server should be a mere cached copy of the data on the filesystem.
Splitted and organized logs. Log events are no more saved on a monolithic log but split into a filesystem structure organized by projects, clients, executions. Former server achieved that but as a post-processor step. Providing full context for the log events facilitates this split on arrival time. This structure also facilitates gathering information like how many executions for a given client with a simple glob.
Cheaper information has it’s own access point. As said before some information can be retrieved in a cheaper way which requires less parsing or no parsing at all. The Server provides interface to get that information directly. This way we ensure that no superfluous parsing is done.
Query results as dynamic attributes. Some structured information from a single source such an execution log is provided as an object with dynamic attributes. Like having a dictionary but accessing it as attributes with meaninful names. Hyde metadata system inspired me that javascriptic approach. It is quite fast to implement in Python and quite confortable to use.
Information caching. Some information bits, such as the completion status of a finished execution or the current status of a given client, require parsing a lot of information to get some bits that can be cached in files. Specific interface for that information will be provided so that eventually the query could rely on the cached information.
One generator class per output file. Original server had all the methods for all the outputs mixed in a single class. It was very hard to understand which methods collaborate to get the same output. I created one class per output, which conveniently groups collaborating methods and you can name them in a simpler way as the class provides context. Common code is mainly information gathering, and has been moved to the Server class.
Not writting files yet. Page classes do not write any files. This eases the testing of the output by checking strings. This could be inconvenient if the generated files get big. A controller WebGenerator class orchestrates the file generators by providing the Server or the specific data.
Rely on Server for ‘now’. Because many functionalities depend on current time, test take control over that variable by using Server’s ‘now’ attribute. It returns the current time unless you set it to an arbitrary one.
New features
Speed. Isn’t it a feature? Yep it is. Splitting logs and reducing the need of parsing them all the time is a huge speed up. Further speed up can be added in the future by caching summarized information from logs, which now can be implemented quite transparently.
Easier to extend: Gathering data is now more easy so adding new features like the ones presented below is now quite easy.
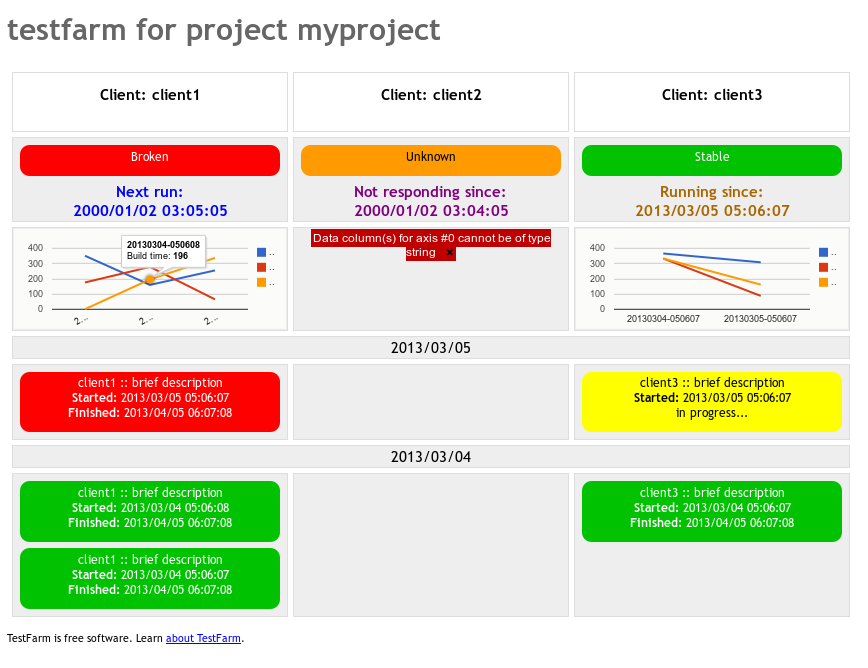
Client summary on top of the history. Now you have a clear indicator at the top of the history page (the former index page) telling the status of every client. It has the status of the last complete execution (red, green, whatever) and the client status (waiting for updates, unresponsive, running). In previous versions you had to scroll down to see the current status of some clients.
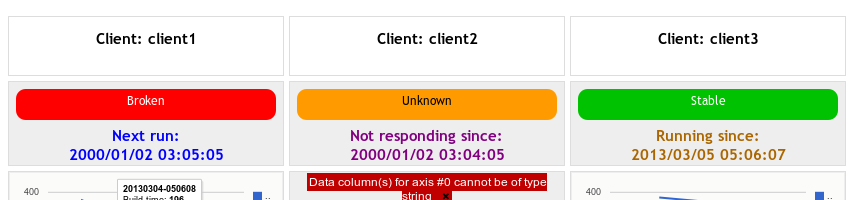
Better stat plots. I got ride of Ploticus. Not that it is bad, but dependencies are a problem if you have to host the service. I used Google’s CoreChart. It gives me nice looking SVG-or-whatever-in-your-browser plots with useful tooltips.

This is at the cost of adding a couple of external javascript files But placing a plot becomes just a matter of writing this HTML:
<div class="plot" src="yourdatafile.json"></div>
and writting in ‘youdatafile.json’:
[ ["Executions", "param1", "param2"], ["20130323-101010", 13, 43], ["20130323-103010", 15, 35], ["20130323-105010", 17, 78], .... ]
JSON based summary page. This feature has been here for a while. But as I had to reimplement it and The summary page is not generated at the server at all. It is fully rendered and updated on the browsing by fetching some json data.

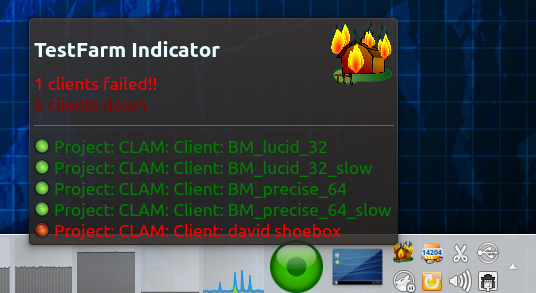
JSON based TestFarm monitor tray icon applet. Also arround for a while but unexplained. testfarm-indicator, a tray icon applet to monitor the status of several testfarm projects without having to visit their web pages. Whenever a client gets red, you will see how the farm icon bursting into flames. It also relies on the JSON data generated for each project.
Status and TODO’s
Web generation is feature complete, replicating what former server did and adding some features. Still the communication between the clients and the server is not implemented. This is a key stage and a requirement before getting it integrated into the stable repository at SourceForge. Meanwhile I am developing it using a separate git repository. By now you can emulate client events and get nice screenshots of the generated web.
So my TODO list on TestFarm has a look like this:
- Connecting the client so that they use the new Server API
- Aborting executions
- Caching gathered information
- Execution summary once finished or aborted
- Client state
- Making it safe to client provided names (that get into the file system!!)
- Web interface for creation and configuration of Projects, adding clients…
- Signed client messages for security
Glossary
- Server: Web-service collecting information from clients to generate TestFarm website for one or many projects.
- Project: Set of clients, often sharing code base, that are displayed side-by-side in a TestFarm web.
- Client: Set of tasks executed once and again in the same environment.
- Execution: Result of executing once the sequence of tasks for a client.
- Task: A sequence of commands under a descriptive label.
- Command: An executed shell statement. Its execution provides an ansi/text output and an status value.
- Command modifiers: functions that parse the output of a command to add extra information.
- Info: generates text that will be always displayed (output is shown just when the command fails)
- Stats: dictionary of numbers. Value evolution along executions will be plotted for each key.
- Success: boolean overriding the command status value