Audio Applications
Index
- Audio Applications
- Environment data sources and sinks
- Real-time and off-line execution
- Processing multiple audio items
- Graphical user interface
- Instant data monitoring
- Real-time control sending
- Transport control and feedback
- Visualization of data along time
- Edition of data along time
- Managing multiple audio items
- Configuration and setup
- Audio application archetypes
- Software synthesizers
- Sound effects
- Sound analyzers
- Music information retrieval systems
- Audio authoring tools
- Sequencers
- Real-time audio applications
- 4MPS Meta-model
- Towards a Pattern Language for Data-flow Architectures
- Summary
This chapter does a domain analysis on the family of systems that we call audio applications. This analysis covers the set of applications to be modelled visually by the prototyping architecture, real-time audio applications, but also extends to some other applications whose development could benefit from such prototyped components.
To get into that point, we analyze common and specific aspects of audio applications, and their related implementation issues. Such aspects range from data exchanges with the outside world, data and time dependencies, in-memory representations, user interface... Then, to probe the validity of such abstraction, we use them to describe some common archetypes of audio applications. Finally we define, based on such abstractions, which are the target applications of visual prototyping and how visual prototyped components could become the building blocks of some other audio applications.
Environment data sources and sinks
This section describes an abstraction how an audio application sees the environment provided by the system.
Normally an audio application is such because it deals with some audio related data sources and sinks: soft synthesizers receive MIDI events coming from other sequencer application, and they send an audio stream to an audio device, while a karaoke application reads time aligned lyrics from a file and displays it with synchronized coloring while it reproduces the song. Audio applications may interact with different sources and sinks of such audio related data. Each one has different requirements on how to be handled:
- Audio streaming
- Asynchronous control events (MIDI, OSC...)
- Serialized information (audio files, meta-data...)

Audio applications takes and feeds data in different forms with the system and with the other applications. Communication have different requirements depending on the type of interface.
Audio Streams
The most common data communication of audio application with the outside world are audio streams. Traditionally, audio streams directly come from (or go to) the audio device driver offered by the system. See figure Fig:AudioStreamsDeviceDriver. Several programming interfaces for audio devices are available. Most of them are platform dependant such as ALSA (Linux), OSS (Unix), Audio Core (MacOs), WMME, DirectSound, ASIO... Some libraries, such as PortAudio[BencinaPortAudio] and RTAudio[RtAudioICMC02], provide a cross-platform view of them all by abstracting common features such as device enumeration, selection, and setup.

Device drivers audio streams: Traditionally, audio streams are provided by system device drivers.
A special kind of application, the audio plug-in, does not take the audio streams from audio devices but from a host application. An audio plug-in is an independently distributed library that can be loaded by any host application. See figure Fig:AudioStreamsHostPlugin. The audio plug-in concept had been used by several audio software as a way of extending their capabilities. The concept gained popularity with the publication of API specifications such as VST that allowed not just developing plug-ins but also hosts applications that could load such plug-ins, fostering the reuse of plug-ins across applications. After VST, many other standards appeared such as the free software based LADSPA and DSSI, or the Audio Units standard on Mac.

Host application is the audio stream provider of the audio plug-ins it loads.
Plug-ins have an asymmetrical relation with their host. Conversely, inter-process audio communication standards such as JACK[LetzJack] enable pear-to-pear communications among applications: Any conforming application can use any other as sink or source for its audio streams. See figure Fig:AudioStreamsInterApp. This allows the connected applications overcome the inherent limitations of being a plug-in. They can have their own application logic and they can communicate with several applications, not just the host.

Inter-application audio communication APIs allow use other applications as source and sinks for audio streams.
Other application use the network as source or sink of audio streaming. Internet audio broadcast applications are examples of application using the network as audio sink. Also most modern audio players are able to play streaming audio coming from the network. Network streaming has to deal with the fact that a given audio frame is not guaranteed to get its destiny in a bounded interval of time. Some internet protocols such as RTP[RTP] deal with such limitations but other applications need to reuse regular protocols. Software layers such as GStreamer \footnote{http://gstreamer.freedesktop.org/} provide a layer that abstracts the idiosyncrasy of such sinks and sources offering application a continuous stream.
Audio streams are accessed through an application programming interface (API). Two common styles of API's are commonly used. In a blocking audio API, the application ask for reading or writing an audio chunk and blocks until the input audio is available or the output audio is required and fed into the device. Of course, the audio application must handle other actions while waiting for the devices, so normally the audio is handled by an independent thread. Callback or event based API's, instead, tell the system to call a given application function (the callback or the event handler) whenever the audio stream is available to be accessed. PortAudio, RTAudio, and ALSA support both styles of API's.

Real-time processing requires the processing of a block to be executed within the duration of such a block.
One of the main traits of audio streams is that they provide or require data at a fixed pace. If data is not read or written at such pace, the application misbehaves. The time slot is equivalent to the time duration of the data that is to be written or read (see figure fig:IdealRealTimeLatency). Read over-runs happen whenever the application is not able to read a data source within its time slot while, write under-runs happen whenever the application is not able to write into a data sink within its time slot. Both are named generically x-runs and they normally are perceived as hops or clicks on the sound.

Time-lines for (a) a well behaving real-time execution, (b) x-run due to a processing peak, (c) x-run due to non-real time scheduling, (d) one period buffering adding latency but absorbing x-runs c and d, and (e) one period buffering not able to compensate several adjacent x-run conditions.
Even when the mean throughput of the CPU is enough to execute the whole processing in less time than the audio duration, the processing may require CPU peaks that go beyond the time slot as in figure fig:XRunsTimelines(b). Also, in systems not enabled for real-time, other threads, processes or even the operating system, may take the time slot, not letting the audio processing to be done on time (figure fig:XRunsTimelines(c)). In both cases, the effect of x-runs can be minimized by adding extra buffering. Figure fig:XRunsTimelines(d), shows how buffering absorbs the x-runs at the cost of latency, that is, the time period since an input event happens until one listens its effects on the output. But as figure fig:XRunsTimelines(e) shows, the number and the relevance of the x-runs to be absorbed depends on the size of the buffering which in turn increases the latency. For applications not requiring low latency, buffering can be very high. But as discussed later, on some applications high latencies are a problem and a trade-off is needed.
In this section, we have been discussing about audio streams. But, of course, most of those considerations can be extended to any synchronous data transfer not being audio. For example, a visualization plug-in may receive from the host player spectra to be visualized at a constant pace.
Asynchronous control events
A different, but also very common, data transfer between audio applications and the outside world are asynchronous control events such as MIDI events [MIDISpecification] sent or received by external MIDI devices, or OSC [WrightOSC-ICMC] messages sent or received by local or remote applications.
They are asynchronous because in contrast with audio streams, they are not to be served in a continuous pace. Receiving audio applications don't know before hand when events will happen. This implies a different kind of problems. Control events may come in bursts, so, when an application also has to deal with real-time synchronous stream, we can get into problems if serving a control event is too expensive. Also, while you can implicitly know the time position of audio streams, just by their ordering and the sampling period, there is no implicit way to know the timing of control events.
Whenever an audio application deals with control events, latency is a concern in any dependant audio stream. For example, a MIDI controlled software synthesizer will misbehave if a note starts too much time later than the user pressed the key on the MIDI keyboard. Live performance is hardly affected by this delay. Brandt and Dannenberg consider acceptable latency of some commercial synthesizers between 5 and 10 ms which is comparable to delays due to acoustic transmission [BrandtLowLatency].
An additional concern with control events is the jitter. When we have two dependant input and output audio streams, the latency is constant and depends just on the buffering sizes \footnote{It also can be variable due to poorly designed audio devices.}. When an output audio stream depends on an input control, latency may be variable producing an effect called jitter (see figure fig:JitterTimeLine). Some studies reported the minimal noticeable jitter on a 100 ms rhythmic period is 5 ms[Noorden1975], 1 ms [Michon1964] and between 3 and 4 ms [Lunney1974]. Of course, not all events has the same effect on the audio. The ones in the studies were onsets of a percussive sound. Jitter perception in other kind of events such as continuous control may be less sensitive.

Different latencies on serving control events results on control jitter.
Dannenberg describes a solution to the jitter problem [DannenbergWICMC]. If we can get time-stamped events from the device, we can set a compromise maximum latency, and applying all the events with constant delay from the time-stamp. Time-stamping also gives problems when the time-stamp clock and the clock reference for real-time audio does not match. Adriaensen [ClockMismatch] proposes a solution to correct the clock mismatch.
File access
Another important outside information flow is the one involving files: Mainly audio files but also files containing meta-data, configuration, sequencing descriptions...
File access has two main traits. On one hand, and in contrast to audio streams and control events, they do not impose any real-time or timing restrictions on how to access data. The application can access file information without any time order restriction, and it can spend many time as it needs to do a computation related to a time slot. On the other hand, accessing files is not real-time safe, in the sense that there is no guaranties of reading or writing a file block within a bounded period of time. Thus, if a real-time process must access a file for reading or writing, it will need intermediate buffering, and dealing the file access in a different thread or after the real-time task in blocking API's. In this case, the buffering does not add latency to the output as file access is not restricted in time.
In summary, if we just deal with files, none of the previous real-time concerns apply, but as we relate them with data sink and sources imposing real-time restrictions we need to separate them with a buffer.
Real-time and off-line execution
Data and time dependencies an application has on external sinks and sources limit the kind of processing the application is able to do. Also, the processing an application is required to do, limits the data and time dependencies the application can have on external data sinks and sources.
For instance, consider an effect plug-in (figure fig:ExecutionModesFXPlugin). An effect plug-in continuously takes sound coming from an input audio stream, modifies it and sends continuously the resulting sound to an output audio stream. Time-data dependencies of such architecture forbids the plug-in to do any transformation that requires information from the future of the stream. It is limited to streaming processing. A very simple streaming process is an amplification effect which multiplies every sample by a constant. No future data is required to apply the amplification to a sample.

Data-time dependency in an effect plug-in
On the other hand, audio normalization is a very simple example of transformation requiring future data, a non-streaming processing. Normalization consists on applying an audio the maximum gain without clipping. Applying the gain is a streaming processing but to know the gain you need to know the maximum level which might be beyond the current processed audio sample. Thus, the full audio excerpt must be analyzed before we can compute the output of the first sample. This is incompatible with the timing and data dependencies imposed by the audio plug-in architecture. \footnote{ Notice that internal application buffering could add some limited look-ahead and extend the future scope at the expense of latency. But this is not enough to solve the normalization problem since we need to know the full excerpt. }

Data-time dependency in an audio editor. The internal audio representation breaks data-time dependency between audio devices, enabling non-streaming algorithms but disabling real-time processing.
To execute a normalization we should have to relax time-data dependencies between input and output audio streams. For example, an audio editing tool (figure fig:ExecutionModesAudioEditor), can apply a normalization by doing it off-line. Off-line execution means that the execution of the process is not bound to any source or sink with real-time restrictions. To achieve that, the audio editor makes use of in-memory representation of the full audio. In-memory representation offers random access to time associated data. File access also would play the role, as explained in section ssec:FileAccess, but, it would need be on a different thread and communicating to the real-time playback using a ring buffer as in figure fig:ExecutionModesFilePlayer.

Data-time dependency in an file player. File reading is isolated in a different thread using a buffer to avoid file system access to block the throughput. This buffering has no effect on real-time latency.
We can get more insight from the normalization example. The computation of the normalization factor (the inverse of the maximum absolute sample value) can be computed in streaming. Being streaming could mean, for example, that it could be computed within the audio capture process. The process has no frame a frame output but a summary output. But still the output can be computed in a progressive way.
On the other hand, given the normalization factor, applying the gain is also a streaming process. We can see that summary computations can be streaming processes, but processes with dependencies on summary computations can not be streaming. We can see also that some non-streaming processes can be expressed by a set of streaming processes communicating summary outputs.
One conclusion of that is that if we have a way of expressing streaming algorithms, such as data-flow systems where the tokens are at frame level, some non-streaming algorithm could be built by connecting streaming algorithms which share tokens at song level. This is a useful feature to be able to reuse components built for a real-time system in an off-line system.
Like audio streams, input control events must be applied on time and output control events must be sent on time. So dependencies on asynchronous control events also imposes streaming processing.
Processing multiple audio items
Not always the dimension driving the execution of an audio related process is the time. Often, the main driving dimension is the audio item, meaning for example a song within a play list or an audio sample in a sample collection. Some examples for such processing is:
- A multimedia player computing the normalization factor for all the files in the collection.
- A learning algorithm accessing a lot of files to learn some concept.
- A song version aligner taking two versions and locating the correspondence points.
- A similarity algorithm comparing full collections with a reference item.
- A collection visualization tool fig:IslandsOfMusic, computing the distance between each pair of audio items.
Notice that every example has a different access pattern on the multiple items. 1 and 2 just applies some off-line process to a sequence of items. While 1 has an output for each file (the gain), 2 has an overall output for all the collection (the learned model). Notice that this has some parallelisms on summary computations along time. Examples 3, 4 and 5 have a core process which has two input items, and the main difference among them is how the items are feed to that core process.
Graphical user interface
The graphical user interface is an actual part of the application. But if we consider it as such, related information flow with the outside would consist just on drawing primitives and low level input events which are not attractive for this discussion. If we consider the full interface as an outside element (with some privileges), information flow will consist in audio relevant information, and this will enrich the description on what is happening with audio applications.
In real-time systems, a sane design places the GUI and the audio processing in separate threads. Having the GUI in a low priority thread helps to meet the real-time requirements by allowing the real-time processing thread to pop up every time it is required. Of course thread separation requires inter-thread communication. In the case, of real-time applications, such inter-thread communication must be lock-free for the real-time thread. Valois describes several lock free structures [ValoisThesis]. The commonly used one for thread communication in audio is the lock-free FIFO queue by Fober et al. [FoberOptimisedLockFreeQueue] [FoberOptimisedLockFreeQueueContinued].
In off-line systems, thread separation is also useful because off-line processing may require too long periods in which the GUI would not respond. But thread separation is not the only solution for off-line systems. The alternative can be a rendez-vous policy: periodically the processing tasks let the user interface to respond any pending incoming user interface event. This simplifies the system not having to deal with thread management and inter-thread communication issues.
User interaction is closely related to the application logic. We identified several archetypical user interaction atoms. Depending on the application logic, several of those atoms will be required, and each interaction atom will bring its own implementation concerns. The user interaction atoms are:
- Instant data monitoring
- Real-time control sending
- Transport control and feedback
- Visualization of data along time
- Edition of data along time
- Visualizing or managing audio items collections
- Configuration and setup
Following sections analyze the traits of each interaction atom and its implementation requirements.
Instant data monitoring
Examples of instant data monitoring: XMMS visualization plug-ins taking instant PCM and spectrum data.
Often audio applications need to display some data that is tied to an instant of the streaming audio. The vu-meter on an audio recorder application, or oscilloscopes and spectrum views on multimedia players (figure fig:InstantDataMonitoring) are common examples.
The common trait of such views is that they require regular updates of information coming from the processing thread. Thus, a thread safe communication is needed.
Also, visualizing every processing data is not required. Indeed is not even feasible as the processing token cadence is at the order of 10ms and the screen retrace at the order of 100ms. This, and the fact that the reading thread has no real-time constraints, will allow us to use a very simple thread safe communication mechanism instead of the typical lock free structures. Such mechanism is explained with more detail at section sec:PortMonitor.
Real-time control sending

Some control knobs in amSynth, a software synthesizer.
A very common user interface functionality in audio applications is to send asynchronous control data that modifies processing in real-time. For instance, the knobs of a real-time software synthesizer, or the mixer slider of a DAW\footnote{DAW stands for Digital Audio Workstation, instances are Ardour, Cubase, ProTools...} which sets the recording gain of an input channel.
Such events coming from the interface should be taken as they where a real-time asynchronous event source. The problem here is that the latency of user interface events is huge because the user interface is in a non-real-time priority thread. Moreover such latency is very variable, because it heavily depends on the queue of graphical events to be served and that causes jitter. Often user interface events are not time stamped so it is difficult to apply them a constant latency to avoid that jitter. And when they are time-stamped they often use a different clock than the audio clock so the drift should be compensated.
Transport control and feedback
A set of user interactions affect the time the audio application is handling. Simple transport actions such as play and stop but also moving the play-head of an audio view or setting cue points, play regions and loops in a time line.

The transport control and feedback interface in Ardour 2.

Detail of the Ardour 2 time bar. The red triangle is the play head indicating the currently playing position. The blue triangle is the cue position where the play head goes back when the playback ends. Loop defines a region to play and punch the region where the saving is active. Range and position markers let save them for later reuse.
At the same time, audio applications often gives feedback of the current transport status for example by moving the play head position, a transport indicator or by displaying the current time.
Transport interactions have sense when performing real-time tasks. But they also have their counter part in off-line processing. Play and stop have similar requirement to launching and aborting an off-line processing. Also, a progress indicator may have very similar behaviour to a transport indicator. But off-line execution might not be a linear time execution so in this case progress indicator might be something different than time.
When more than one audio item are involved, often audio item change is another transport control interaction for controlling and having feedback on. Transport changes can be handled in a similar way control sending is done. The specifics for transport is that such interaction may need more interaction than simply sending events to the processes.
Visualization of data along time
Non-Instant data-time visualizations display data bound to time along the time. The most clear example is waveform visualization but also spectrograms or even the structural representation of a song. Such visualizations need a data source that is not real-time such as file access or in-memory representation.
Being just visualization the only interaction with the audio application are updates when other process changes such data.
When programming such views, other process modifying the in-memory representation could be an issue, but as the interface thread does not modify the representation, normally lock-free communication mechanism are not needed.
Several views from Audacity: Spectrogram and waveform.

Sonic Visualisers presents static data along the time in many different ways.
Edition of data along time
Another common interaction between the GUI and the application is direct manipulation of time related data. For example, placing and editing notes in an score editor, arranging patterns in a sequencer or placing and moving waves along tracks in a digital audio workstation.
In edition, concerns applied to non-instant data-time visualisation also applies here: They require in-memory representation of the data, and data updates to the visualization. Besides that, edition is not just passive and it also modifies the in-memory representation, such changes could interfere with some running real-time or off-line process. Again, lock-free thread communication is needed.

Hydrogen drum machine allows editing when the events will happen along the time.
Managing multiple audio items
Often audio applications have to deal with a collection of audio items and offers the user views to visualize or manage such collection. Simple examples could be a play list editor (figure fig:Amarok) or a sample collection browser. But such views could be more elaborated [IslandsOfMusic] as shown in figure fig:IslandsOfMusic.

Amarok multimedia player showing the collection browser (left) and the play list editor (right).

Three dimensional interface for exploring collections
Also applications has views or edition interface for information related to a single audio item as a whole. For example, an application could allow to edit the ID3 tags of a song or adding custom labels. It could also display context information: artwork, artist biography and other meta-data. Such information is time independent, those components just need to know when they item information must be feed.
Because audio items visualization and management doesn't impose any real-time constraint, this kind of interaction is feasible for web applications. Some illustrative web applications dealing with audio items are Foafing The Music[FoafingTheMusic]\footnote{http://foafingthemusic.iua.upf.edu}, Last FM \footnote{http://www.lastfm.com}, and Music Brainz \footnote{http://musicbrainz.org.}.
Configuration and setup
Besides multi-item interactions, other set of interactions that are time independent are the ones for configuring and setup the application. For example, setting up a process before launching it, or setting up audio and event streams.
Audio application archetypes
This section identifies some of the functional roles of existing and foreseen audio applications, and describes them in terms of data transfers with their environment, internal representations and execution modes. The goal is to demonstrate that the former abstractions are enough to describe the internal application structure of a relevant group of audio applications.
The roles described below are very abstract. Actual audio software may be a combination of several of those roles.
Software synthesizers
Software synthesizers generate sound in response to incoming events. The application logic of this kind of software requires very few interactions with the user:
- Setting up the sound by controlling parameters, sound banks, presets...
- Receiving control events from the GUI (when available).
The main process of a software synthesizers is real-time constrained by a link between incoming control events stream and the audio output stream. Thus, events should be time-stamped and be applied with a constant delay. Some software synthesizes deal with input coming from the user interface. Such input events as explained in section sec:UIControl need an special care.
Also, the synthesizer could have some instant view of the produced audio. Figure fig:Salto shows a software synthesizer called Salto which displays some instant views related to the produced sound.

Salto, a software synthesizer developed at the UPF, which uses spectral models to synthesize sax and trumpet sounds.
Off-line synthesizers also exist but they are not as common as real-time ones. They are used when real-time rendering is not feasible, for example when complex generation models are used, such some physical modeling algorithms. In this case the control events come in a file representations. For example, in CSound the sound generator setup comes in the orchestra file while the control events are specified on the score file. MIDI files are also common event source for off-line synthesis.
Sound effects
Sound effects take the audio input and perform modifications to produce an output. They share most characteristics with sound generator but they also must deal with the input stream which is real-time linked with the output. Recent audio effects tend to be audio plug-ins as this makes them more reusable.
Off-line processing is more common in processor than with sound generators. Nice examples of off-line effect processor are ecasound\footnote{http://eca.cx/ecasound/} and SoX \footnote{http://sox.sourceforge.net/}.
Sound analyzers
Sound analyzers take some input sound and they extract a different representation. Such representation could have different uses. Real-time analyzers are used to give visual feedback on an audio stream. They are also used as control mean in performances. For example, we could detect the chords of the audio in order to perform an accompaniment arpeggio. This kind of tasks require real-time restrictions between the input and the output data.
Typical sound analyzers require few interaction:
- Analysis parameter setup
- Output visualization
Off-line sound analyzers are more frequent than real-time ones often simply because the processing load is to heavy for real-time requirements, but also because non-streaming processing is needed. For example, some analysis done in music information retrieval need having a global view of the excerpt or they have dependencies on summary results. Also music information retrieval systems (described below) require the output of analysis performed to many audio items, and such a batch analysis is done off-line.
Music information retrieval systems
Music information retrieval systems deal with a lot of audio items. In order to deal with such amount of audio material they use summarized information taken with some batch analysis process. So the abstractions on supporting multiple audio items in processing (section sec:MultipleAudioItems) and interface (section sec:MultipleAudioItemsView) can be applied to off-line analysis for music information retrieval.
Audio authoring tools
Audio authoring tools are applications such as Sweep, Audacity, GoldWave, CoolEdit... They respond to the schema previously shown on figure fig:ExecutionModesAudioEditor. They have an in-memory representation of the audio and perform off-line processing to it.
Common interactions in this kind of software are:
- Recording audio
- Loading and saving files
- Transport management (play, stop, range selection...)
- Launching and cancelling off-line processes
- Playing audio
Sequencers
Sequencers are programs that allow the users to edit a representation of the structure of a song. Such structure contains data which is used to control internal or external sound producers, typically a synthesizer. They often have a recording mode to input events from an external device such a MIDI keyboard.
Free software applications that includes such a role are Rosegarden, MuSe, NoteEdit, Hidrogen, CheeseTracker... All those application use different paradigms on how the user edits the structure: score, piano role, pattern sequencer, tracker... Even thought, the concerns on edition are nearly the same.
Sequencers have to deal with several user interactions:
- Selecting or configuring the sound producers.
- Recording and editing events into the song structure
- Edit the song structure
- Transport control
This software has an in-memory representation of the events along the time. In normal playback, the real-time constraints apply to the control sending. In-memory representation of the events enables using a forward scheduling. In recording mode, if available, often the input events are required to be forwarded to the output so they can have effect on the sound producer and provide feedback to the performer user. Because that, in that case, there is a real-time link between received and sent control events.
Real-time audio applications
Previous section has provided some insight on the inner structure of several archetypes of audio applications. In this section, we give deeper insight on the subset of real-time audio applications: How can they be modelled in a general way, which roles can they perform, and which are the main implementation concerns. We also explain how components of a real-time audio applications can be reused in other contexts.

A generic schema of a real-time application. The application contains a single streaming process which may take and send data from and to audio streams, control event streams or files. The application interface may provide instant data visualization, GUI control event sending and transport control and feedback.
Figure fig:RealTimeApplicationModel, is a generalization of the family of applications that we call real-time audio applications. That is the set of applications whose visual building is addressed in this work. Such applications include a single streaming process that may deal with:
- several input and output audio streams,
- several input and output event streams (MIDI, OSC...), and,
- several input and output file streams.
The application could provide user interface for
- controlling transport (start, stop the process and seek on the file sources,
- having feedback on the transport state,
- instant data visualization,
- sending control events from the interface,
- setting up the sinks and sources to deal with (not in the figure).
This description fits the needs of some of the roles described on the previous section: real-time software synthesizers, real-time sound effects, and real-time audio analyzers.
Some other application archetypes such as authoring tools, sequencers, music information retrieval system and off-line systems are outside this description. The key features that make them out are:
- Non-streaming processing
- In-memory representations
- Multiple audio item processing
- Any other application logic that is more complex than binding to external streams, starting, stopping, control the transport on file based streams, sending control events and visualizing instant data.
Anyway, in section sec:ReusingInNonRealTime, we explain how components built with the prototyping architecture can be helpful to build applications outside this scope.
4MPS Meta-model
This section goes into the details of the streaming processing element of the real-time application schema shown in the figure fig:RealTimeApplicationModel. We describe a domain-specific meta-model called 4MPS. 4MPS is the conceptual framework for the data-flow language to be used in the prototyping architecture for the audio processing.
The Object-Oriented Metamodel\footnote{The word metamodel is here understood as a ``model of a family of related models'', see [AmatriainThesis] for a thorough discussion on the use of metamodels and how frameworks generate them.} for Multimedia Processing Systems, 4MPS for short, provides the conceptual framework (metamodel) for a hierarchy of models of media processing systems in an effective and general way. The metamodel is not only an abstraction of many ideas found in the CLAM framework but also the result of an extensive review of similar frameworks (see section multimediaframeworks) and collaborations with their authors. Therefore the metamodel reflects ideas and concepts that are not only present in CLAM but in many similar environments. Although initially derived for the audio and music domains, it presents a comprehensive conceptual framework for media signal processing applications. In this section we provide a brief outline of the metamodel, see [xamatIEEEMM] for a more detailed description.
The 4MPS metamodel is based on a classification of signal processing objects into two categories: \emph{Processing} objects that operate on data and control, and \emph{Data} objects that passively hold media content. Processing objects encapsulate a process or algorithm; they include support for synchronous data processing and asynchronous event-driven control as well as a configuration mechanism and an explicit life cycle state model. On the other hand, Data objects offer a homogeneous interface to media data, and support for metaobject-like facilities such as reflection and serialization.
Although the metamodel clearly distinguishes between two different kinds of objects the managing of Data constructs can be almost transparent for the user. Therefore, we can describe a 4MPS system as a set of Processing objects connected in graphs called Networks (see Figure fig:CLAMProcessingNetwork).

Graphical model of a 4MPS processing network. Processing objects are connected through ports and controls. Horizontal left-to-right connections represents the synchronous signal flow while vertical top-to-bottom connections represent asynchronous control connections.
Because of this the metamodel can be expressed in the language of graphical models of computation as a \emph{Context-aware Data-flow Network} (see [LeeAndTomasDataflowNetworks] and [DijkContextAwareProcessNetworks]) and different properties of the systems can be derived in this way.
Figure~fig:CLAMProcessing is a representation of a 4MPS processing object. Processing objects are connected through channels. Channels are usually transparent to the user that should manage Networks by simply connecting ports. However they are more than a simple communication mechanism as they act as FIFI queues in which messages are enqueued (produced) and dequeued (consumed).

4MPS Processing object detailed representation. A Processing object has input and output ports and incoming and outgoing controls. It receives/sends synchronous data to process through the ports and receives/sends control events that can influence the process through its controls. A Processing object also has a configuration that can be set when the object is not running.
The metamodel offers two kinds of connection mechanisms: ports and controls. Ports transmit data and have a synchronous data-flow nature while controls transmit events and have an asynchronous nature. By synchronous, we mean that messages are produced and consumed at a predictable ---if not fixed--- rate.
A processing object could, for example, perform a low frequency cut-off on an audio stream. The object will have an input-port and an out-port for receiving and delivering the audio stream. To make it useful, a user might want to control the cut-off frequency using a GUI slider. Unlike the audio stream, control events arrive sparsely or in bursts. A processing object receives that kind of events through controls.
The data flows through the ports when a processing is triggered (by receiving a Do() message). Processing objects can consume and produce at different rates and consume an arbitrary number of tokens at each firing. Connecting these processing objects is not a problem as long as the ports are of the same data type (see the \emph{Typed Connections} pattern in section sec:TypedConnections). Connections are handled by the {\em FlowControl}. This entity is also is responsible for scheduling the processing firings in a way that avoids firing a processing with not enough data in its input ports or not enough space into its output ports. Minimizing latency and securing performance conditions that guarantee correct output (avoiding underruns or deadlocks, for instance) are other responsibilities of the FlowControl.
Life-cycle and Configurations
A 4MPS Processing object has an explicit lifecycle made of the following states: \emph{unconfigured}, \emph{ready}, and \emph{running}. The processing object can receive controls and data only when running. Before getting to that state though, it needs to go through the \emph{ready} having received a valid \emph{configuration}.
Configurations are another kind of parameters that can be input to Processing objects and that, unlike controls, produce expensive or structural changes in the processing object. For instance, a configuration parameter may include the number of ports that a processing will have or the numbers of tokens that will be produced in each firing. Therefore, and as opposed to controls that can be received at any time, configurations can only be set into a processing object when this is not in running state.
Static vs. dynamic processing compositions
When working with large systems we need to be able to group a number of independent processing objects into a larger functional unit that may be treated as a new processing object in itself.
This process, known as composition, can be done in two different ways: statically at compile time, and dynamically at run time (see [DannenbergAuraICMC04]). Static compositions in the 4MPS metamodel are called Processing Composites while dynamic compositions are called Networks.
Choosing between Processing Composites and Networks is a trade-off between efficiency versus understandability and flexibility. In Processing Composites the developer is in charge of deciding the behavior of the objects at compile time and can therefore fine-tune their efficiency. On the other hand Networks offer an automatic flow and data management that is much more convenient but might result in reduced efficiency in some particular cases.
Processing Networks
Nevertheless Processing Networks in 4MPS are in fact much more than a composition strategy. The Network metaclass acts as the glue that holds the metamodel together. Figure clam-processing-network-class depicts a simplified diagram of the main 4MPS metaclasses.
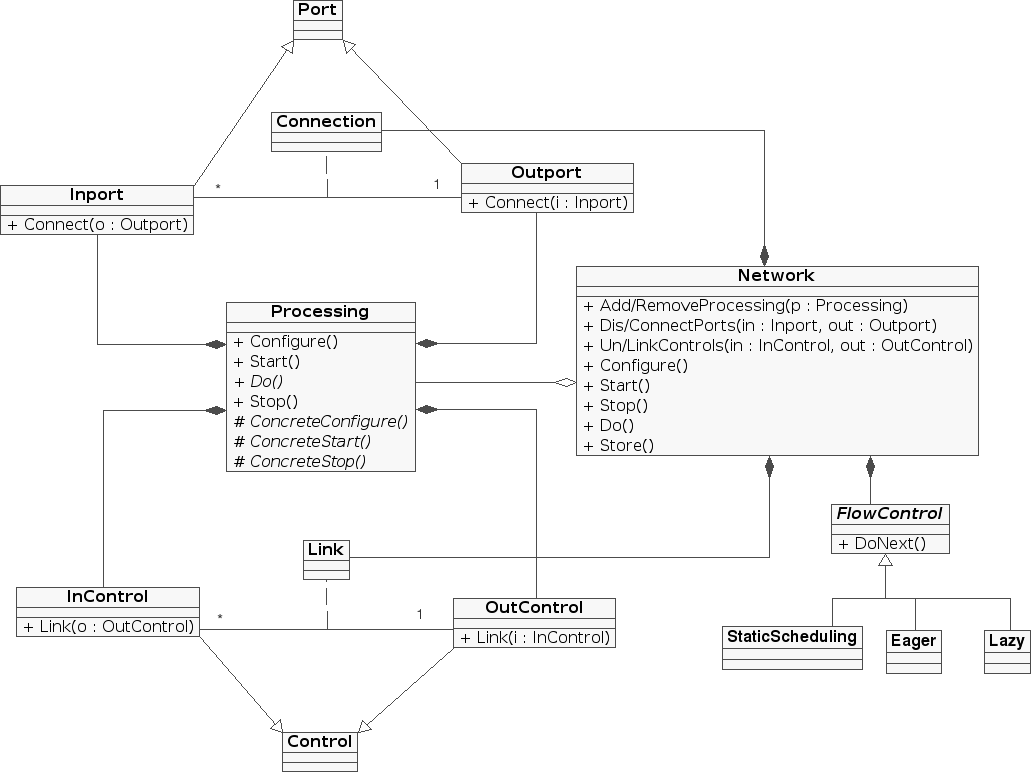
Participant classes in a 4MPS Network. Note that a 4MPS Network is a dynamic run-time composition of Processing objects that contains not only Processing instances but also a list of connected Ports and Controls and a Flow Control.
Networks offer an interface to instantiate new processing objects given a string with its class name using a processing object factory and a plug-in loader. They also offer interface for connecting the processing objects and, most important, they automatically control their firing.
This firing scheduling can follow different strategies by either having a static scheduling decided before hand or implementing a dynamic scheduling policy such as a push strategy starting firing the up-source processings, or a pull strategy where we start querying for data to the most down-stream processings. As a matter of fact, these different strategies depend on the topology of the network and can be directly related to the different scheduling algorithms available for data-flow networks and similar graphical models of computation (see [ParksPhD] for an in-depth discussion of this topic. In any case, to accommodate all this variability the metamodel provides for different FlowControl sub-classes which are in charge of the firing strategy, and are pluggable to the Network processing container.
Towards a Pattern Language for Data-flow Architectures
Introduction
As explained in the previous section, the general 4MPS Metamodel can be interpreted as a particular case of a Data-flow Network. Furthermore, when reviewing many frameworks and environments related to CLAM (see section multimediaframeworks) we also uncovered that most of these frameworks end up offering a variation of data-flow networks.
While 4MPS offers a valid high-level metamodel for most of these environments it is sometimes more useful to present a lower-level architecture in the language of design patterns, where recurring and non-obvious design solutions can be shared. Thus, such pattern language bridges the gap between an abstract metamodel such as 4MPS and the concrete implementation given a set of constraints.
Patterns provide a convenient way to formalize and reuse design experience. However, neither data-flow systems nor other audio-related areas have yet received many attention on domain-specific patterns. The only previous efforts in the audio domain that we are aware of are several Music Information Retrieval patterns [AucouturierThesis] and a catalog with 6 real-time audio patterns presented in a Workshop [www-Dannenberg]. In the general multimedia field there are some related pattern languages like [MultimediaCommunicationPatterns] but these few examples have a narrower scope than the one here presented.
There have been previous efforts in building pattern languages for the data-flow paradigm, most noticeably the one by Manolescu [ManolescuDataflowPatterns]. However, the pattern language here presented is different because it takes our experience building generic audio frameworks and models [AmatriainThesis] [www-CLAM] and maps them to traditional Graphical Models of Computation. The catalog is already useful for building systems in the Multimedia domain and aims at growing (incorporating more patterns) into a more complete design pattern language of that domain.
In the following paragraphs we offer a brief summary of a complete pattern language for Data-flow Architecture in the Multimedia domain presented in [ArumiPlop06]. As an example we also include the more detailed description of two of the most important patterns in the catalog.
All the patterns presented in this catalog fit within the generic architectural pattern defined by Manolescu as the \textsf{Data Flow Architecture} pattern. However, this architectural pattern does not address problems related to relevant aspects such as message passing protocol, processing objects execution scheduling or data tokens management. These and other aspects are addressed in our pattern language, which contains the following patterns classified in three main categories:
\begin{itemize} \itemGeneral Data-flow Patterns address problems of how to organize high-level aspects of the data-flow architecture, by having different types of module connections. {\sf Semantic Ports} addresses distinct management of tokens by semantic; {\sf Driver Ports} addresses how to make modules executions independently of the availability of certain kind of tokens. {\sf Stream and Event Ports} addresses how to synchronize different streams and events arriving to a module; and, finally, {\sf Typed Connections} addresses how to deal with typed tokens while allowing the network connection maker to ignore the concrete types.
\itemFlow Implementation Patterns address how to physically transfer tokens from one module to another, according to the types of flow defined by the {\em general data-flow patterns}. Tokens life-cycle, ownership and memory management are recurrent issues in those patterns. {\sf Cascading Event Ports} addresses the problem of having a high-priority event-driven flow able to propagate through the network. {\sf Multi-rate Stream Ports} addresses how stream ports can consume and produce at different rates; {\sf Multiple Window Circular Buffer} addresses how a writer and multiple readers can share the same tokens buffer. and {\sf Phantom Buffer} addresses how to design a data structure both with the benefits of a circular buffer and the guarantee of window contiguity.
\itemNetwork Usability Patterns address how humans can interact with data-flow networks. {\sf Recursive Networks} makes it feasible for humans to deal with the definition of large complex networks; and {\sf Port Monitor} addresses how to monitor a flow from a different thread without compromising the network processing efficiency. \end{itemize}
Two of these patterns, Typed Connections and Port Monitor, are very central to the implementation of the visual prototyping architecture. Thus, we provide here a summarized version of these patterns. Complete versions of these and the rest of the patterns in the catalog can be found in [ArumiPlop06].
\subsection{Pattern: Typed Connections}
\label{sec:TypedConnections} \subsubsection*{Context}
Most multimedia data-flow systems must manage different kinds of tokens. In the audio domain we might need to deal with audio buffers, spectra, spectral peaks, MFCC's, MIDI... And you may not even want to limit the supported types. The same applies to events (control) channels, we could limit them to floating point types but we may use structured events controls like the ones in OSC [WrightOSC-ICMC].
Heterogeneous data could be handled in a generic way (common abstract class, void pointers...) but this adds a dynamic type handling overhead to modules. Module programmers should have to deal with this complexity and this is not desirable. It is better to directly provide them the proper token type. Besides that, coupling the communication channel between modules with the actual token type is good because this eases the channel internal buffers management.
%xamat: august 07: I am not sure at this point is it clear enough what these ``internal buffers'' mean. In %the 4MPS section we talk about FIFO queues but do not give more details. Do you think this should be somehow %detailed maybe in that same 4MPS section?
But using typed connections may imply that the entity that handles the connections should deal with all the possible types. This could imply, at least, that the connection entity would have a maintainability problem. And it could even be unfeasible to manage when the set of those token types is not known at compilation time, but at run-time, for example, when we use plugins.
\subsubsection*{Problem} Connectible entities communicate typed tokens but token types are not limited. Thus, how can a connection maker do typed connections without knowing the types?
\subsubsection*{Forces}
\begin{itemize}\item Process is cost-sensitive and should avoid dynamic type checking and handling. \item Connections are done in run-time by the user, so mismatches in the token type should be handled. \item Dynamic type handling is a complex and error prone programming task, thus, placing it on the connection infrastructure is preferable than placing it on concrete modules implementation. \item Token buffering among modules can be implemented in a wiser, more efficient way by knowing the concrete token type rather than just knowing an abstract base class. \item The collection of token types evolves and grows and this should not affect the infrastructure. \item A connection maker coupled to the evolving set of types is a maintenance workhorse. \item A type could be added in run time. \end{itemize}
\subsubsection*{Solution}

Class diagram of a canonical solution of Typed Connections
%xamat august 07: it would be nice to relate this figure to UML diagram in figure 4
Split complementary ports interfaces into an abstract level, which is independent of the token-type, and a derived level that is coupled to the token-type. Let the connection maker set the connections thorough the generic interface, while the connected entities use the token-type coupled interface to communicate each other. Access typed tokens from the concrete module implementations using the typed interface.
The class diagram for this solution is shown in figure~fig:classesTypedConnections.
Use run-time type checks when modules get connected (binding time) to get sure that connected ports types are compatible, and, once they are correctly connected (processing time), rely just on compile-time type checks.
To do that, the generic connection method on the abstract interface ({\tt bind}) should delegate the dynamic type checking to abstract methods ({\tt isCompatible}, {\tt typeId}) implemented on token-type coupled classes.
\subsubsection*{Consequences}
The solution implies that the connection maker is not coupled to token types. Just concrete modules are coupled to the token types they use.
Type safety is ensured by checking the dynamic type on binding time and relying on compile time type checks during processing time. So this is both efficient and safe.
Because both sides on the connection know the token type, buffering structures can deal with tokens in a wiser way when doing allocations, initializations, copies, etc.
Concrete modules just access to the static typed tokens. So, no dynamic type handling is needed.
Besides the static type, connection checking gives the ability to do extra checks on the connecting entities by accessing semantic type information. For example, implementations of the bind method could check that the size and scale of audio spectra match.
\subsection{Pattern: Port Monitors} \label{sec:PortMonitor} \subsubsection*{Context}
Some multimedia applications need to show a graphical representation of tokens that are being produced by some module out-port. While the visualization needs just to be fluid, the process has real-time requirements. This normally requires splitting visualization and processing into different threads, where the processing thread is scheduled as a high-priority thread. But because the non real-time monitoring must access to the processing thread tokens some concurrency handling is needed and this often implies locking in the two threads.
\subsubsection*{Problem}
We need to graphically monitor tokens being processed. How to do it without locking the real-time processing while keeping the visualization fluid?
\subsubsection*{Forces}
\begin{itemize}\item The processing has real-time requirements (i.e. The process result must be calculated in a given time slot) \item Visualizations must be fluid; that means that it should visualize on time and often but it may skip tokens \item The processing is not filling all the computation time
\end{itemize}
\subsubsection*{Solution}
The solution is to encapsulate concurrency in a special kind of process module, the Port monitor, that is connected to the monitored out-port. Port monitors offers the visualization thread an special interface to access tokens in a thread safe way. Internally they have a lock-free data structure which can be simpler than a lock-free circular buffer since the visualization can skip tokens.
To manage the concurrency avoiding the processing to stall, the Port monitor uses two alternated buffers to copy tokens. In a given time, one of them is the writing one and the other is the reading one. The Port monitor state includes a flag that indicates which buffer is the writing one. The Port monitor execution starts by switching the writing buffer and copying the current token there. Any access from the visualization thread locks the buffer switching flag. Port execution uses a try lock to switch the buffer, so, the process thread is not being blocked, it is just writing on the same buffer while the visualization holds the lock.
A port monitor with its switching two buffers
\subsubsection*{Consequences}
Applying this pattern we minimize the blocking effect of concurrent access on two fronts. On one side, the processing thread never blocks. On the other, the blocking time of the visualization thread is very reduced, as it only lasts a single flag switching.
In any case, the visualization thread may suffer starvation risk. Not because the visualization thread will be blocked but because it may be reading always from the same buffer. That may happen if every time the processing thread tries to switch the buffers, the visualization is blocking. Experience tell us that this effect is not critical and can be avoided by minimizing the time the visualization thread is accessing tokens, for example, by copying them and release.
\subsection{Patterns as a language}
Some of the patterns in the catalog are very high-level, like {\sf Semantic Ports} and {\sf Driver Ports}, while other are much focused on implementation issues, like {\sf Phantom Buffer}). Although the catalog is not domain complete, it could be considered a pattern language because each pattern references higher-level patterns describing the context in which it can be applied, and lower-level patterns that could be used after the current one to further refine the solution. These relations form a hierarchical structure drawn in figure~fig:patternsRelations. The arcs between patterns mean ``enables'' relations: introducing a pattern in the system enables other patterns to be used.

The multimedia data-flow pattern language. High-level patterns are on the top and the arrows represent the order in which design problems are being addressed by developers.
The catalog shows how to approach the development of a complete data-flow system in an evolutionary fashion without the need to do big up-front design. The patterns at the top of the hierarchy suggest to start with high level decisions, driven by questions like: ``do all ports drive the module execution?'' And ``does the system have to deal only with stream flow or also with event flow?'' Then move on to address issues related to different token types such as: ``do ports need to be strongly typed while Connectible by the user?'', or ``do the stream ports need to consume and produce different block sizes?'', and so on. On each decision, which will introduce more features and complexity, a recurrent problem is faced and addressed by one pattern in the language.
%PAU: he mogut aquest apartat que anava abans de patterns as a language. El problema era % que ara, posant patrons resumits, falta un separador. The above patterns are inspired by our experience in the audio domain. Nevertheless, we believe that those have an immediate applicability in the more general multimedia domain.
As a matter of fact, all patterns in the ``general data-flow patterns'' category can be used on any other data-flow domain. {\sf Typed Connections}, {\sf Multiple Window Circular Buffer } and {\sf Phantom Buffer} have applicability beyond data-flow systems. And, regarding the {\sf Port Monitor} pattern, though its description is coupled with the data-flow architecture, it can be extrapolated to other environments where a normal priority thread is monitoring changing data on a real-time one.
Most of the patterns in this catalog can be found in many audio systems. However, examples of a few others (namely {\sf Multi-rate Stream Ports}, {\sf Multiple Window Circular Buffer } and {\sf Phantom Buffer}) are hard to find outside of CLAM so they should be considered innovative patterns (or proto-patterns).
Summary
This chapter has done a domain analysis of the program family which includes the applications related to audio and music. Some abstractions has been extracted such the ones addressing the system data input and output, user interface interactions, several processing regimes and the implementation issues and solutions related to them. Then we used such abstractions to model several archetypical audio applications, and finally, we also used such abstraction to define the sub-family of applications that are to be visually built by the prototyping architecture. The abstractions also gave some guidelines on how the prototyped components could be used in the set of applications that fall away of the selected sub-family.